物理学家所理解的熵:从热力学、统计物理,到生成模型
物理学的热力学第二定律称为“熵增定律”。它揭示了一个残酷的事实:一个孤立系统总是自发地向着无序发展,总熵值会一直增大,直至达到热平衡。

导语
从“万物终将腐朽”的熵增定律出发,本文系统梳理了熵在热力学与统计物理中的严格定义,展示其如何作为连接微观与宏观的核心桥梁,并进一步走向量子体系、非平衡过程,乃至生成式人工智能模型,揭示熵在理解复杂系统与智能涌现中的深层意义。
关键词:熵增定律、统计物理、玻尔兹曼熵、系综理论、配分函数、非平衡态、生成模型

“根据热力学第二定律,世间万物,迟早会烂掉。”这是伍迪·艾伦电影中的一句台词。
物理学的热力学第二定律称为“熵增定律”。它揭示了一个残酷的事实:一个孤立系统总是自发地向着无序发展,总熵值会一直增大,直至达到热平衡。在这里,“熵”是衡量混乱程度的物理量,熵值越高,系统越混乱(如图1所示)。 照此推演,宇宙的未来注定将走向无序,最终归于沉寂与虚无。
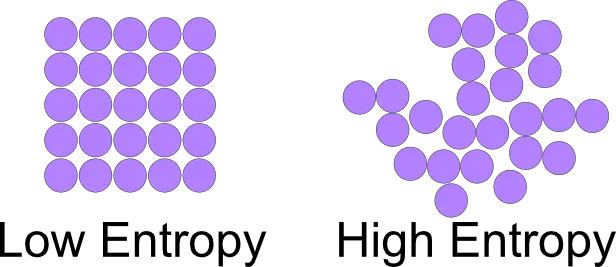
图1:两种系统的熵对比
收回蔓延的思绪,作为一个物理量,那么物理学家是如何定义并计算“熵”?
一、 熵:从热力学到统计物理
一、 熵:从热力学到统计物理
1)热力学定义:从可测过程出发
熵,这个概念来源于热力学。在经典热力学中,德国物理学家克劳修斯把熵定义为“能量的退化”,他创造了entropy(德语 Entropie)这个词,包含能量(对应en)和转变(对应tropy)两种意思,也就是在一个孤立系统中,热量总是从高温流向低温,同时这个过程不可逆。克劳修斯熵的公式为:
dS=dQ/T(1)
其中,S代表熵,Q代表热量,T代表温度,这个公式表明微小熵变等于系统吸收(或放出)的微小热量除以绝对温度,熵的单位就是焦耳/开尔文 (J/K)。
其实中文的“熵”这个字,也和这个公式有关。1923年我国物理学前辈胡刚复教授首次把Entropy翻译为“熵”,这是一个创造的新字,“火”字旁提示它出身于热学语境;“商”在数学中表示除法运算(热力学Q和温度T)的结果。
2)统计物理定义:从微观计数出发
克劳修斯是从可测的热力学过程出发,用宏观物理量定义了熵。熵还有一个著名的表达式,它由玻尔兹曼提出,也被刻在他的墓碑之上:
S = kB logΩ(2)
其中kB其中代表玻尔兹曼常数(单位:J/K),Ω代表满足同一宏观约束(能量、体积等)时系统可实现的微观状态数。宏观上我们只描述少数变量,微观上却存在海量细节,Ω越大,宏观描述遗漏的信息越多,熵也越大。这个公式使用统计的方法来定义物理量,这也是统计物理一个直观的意义。玻尔兹曼从微观状态数变化的角度,用统计物理的方法定义了熵,将宏微观联系起来。
而这两个公式科学家通过推导可以证明,两者是等同的。所以说,熵是统计物理与热力学之间关键的桥梁之一。
当我们把视野从热力学系统拉到复杂系统:当系统由海量自由度构成(粒子、细胞、个体、节点……),我们往往只掌握局部规则与少数约束。统计物理提供的一种基本思路是:虽然不了解系统每个个体的具体行为,但只要个体数量足够多,可以通过忽略细节噪声,来抓住宏观规律。
集智学园联合上海大学李永乐教授推出了《统计物理基础》课程,带你进入到物理的世界中思考,它不是一门枯燥理论或公式推导的课程,因为有些推动物理学的重要公式也并非是通过严格的数学推导得到的,而是一门锻炼物理思考能力的课程,从无序中发现有序,从微观到宏观,来为复杂系统进行建模。
二、辨别熵的多面面孔
二、辨别熵的多面面孔
我们也要注意区分在日常生活中经常听到的“熵”:
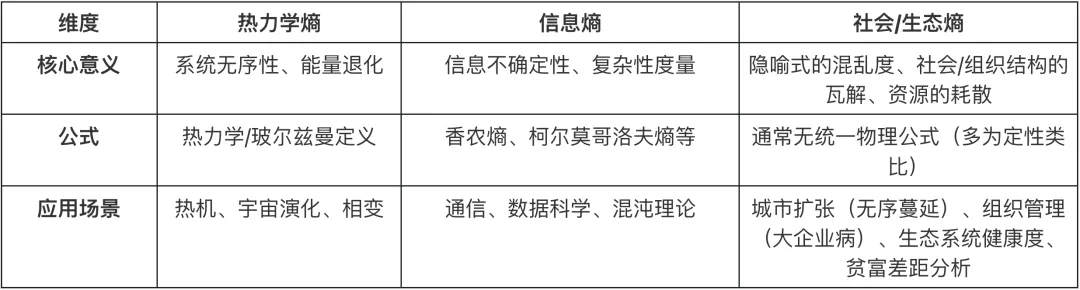
信息熵(香农熵): 这是香农借用了物理学的名词,用来描述信息的不确定性,单位通常为bit。虽然它关注的是信号的概率分布而非能量转换,但它与物理学中的玻尔兹曼熵在数学形式上是完全一致的。这种深层的同构性,为后来物理学家用统计力学解释人工智能埋下了伏笔。
社会/生态熵: 这是一个隐喻式的延伸。将社会的复杂性或能源的耗散称为“熵增”,虽然在宏观直觉上成立,但往往忽略了物理学中极其严格的“孤立系统”前提。
三、逻辑的阶梯:统计物理的基础框架
三、逻辑的阶梯:统计物理的基础框架
统计物理构建了一座连接微观粒子行为与宏观物质属性的严密逻辑桥梁。它摆脱了牛顿力学对单体轨迹的机械追踪,转而引入相空间这一概念——在相空间中,系统中微观粒子瞬时位置与速度的信息浓缩为一个点。在此基础上,统计物理以熵为核心,不再关心个体的信息,而是通过相空间中的概率分布来刻画系统的演化方向。
该理论体系以热力学公理为基石,利用系综理论——一种通过构建大量假想副本来进行统计抽样的方法——将原本复杂的物理问题重构为统计计数问题。在此基础上,确立了配分函数连接起微观能级与宏观观测量。从经典的玻尔兹曼分布到量子统计的全同性原理,再到描述相变与涨落的非平衡领域,统计物理成功地从庞杂的微观概率中提炼出确定性的宏观定律,可谓是纲举目张,一叶知秋。
1)相空间:用分布替代轨迹
在牛顿力学的宏伟版图下,我们习惯于通过解析每一个粒子的受力与轨迹来计算未来的运动。然而,面对一个包含 1023 量级粒子的宏观系统,这种个体追踪的方法论无异于大海捞针。统计物理的出发点很朴素:我们承认细节不可得,于是转向更可控的对象——概率与约束。熵在这里获得一种更精确的身份:它度量在既定宏观约束下,系统还剩下多少“微观可能性”,并由此牵引出宏观演化的方向。
为了承载这种“以概率代替轨迹”的方法,统计物理引入相空间:系统的一个微观态对应相空间中的一个点;系统对外呈现的宏观状态,对应相空间中一大片区域。我们不再纠缠单个点的命运,而关心系统在相空间中的概率分布如何随时间流动。把演化写成分布的变化,熵就自然登场:它衡量分布“铺开”的程度,也衡量约束之下可实现微观态集合的体量。
2)基础理论:熵是连接宏微观的桥梁
玻尔兹曼熵将一个宏观状态理解为大量微观实现方式的集合,其大小的对数自然成为衡量系统“最可能呈现何种状态”的尺度。在此基础上,熵极大原理并非引入额外假设,而是对大数规律的物理表达:系统几乎必然停留在微观实现数占据压倒性优势的宏观状态附近。进一步地,当约束条件以平均量的形式给出时,最大熵原理直接导出玻尔兹曼分布及其配分函数。由此,统计物理建立起一套标准化的跨尺度协议:从微观哈密顿量出发,通过熵的极值化构造配分函数,再由其系统性地生成能量、自由能及响应函数等宏观物理量。所谓确定性的热力学定律,并非概率描述的对立面,而正是从庞杂无序的概率结构中被“提炼”出的最稳定结果。
构建这一逻辑阶梯的首要环节,是对宏观热力学框架的公理化完善。逻辑的严密性要求我们:只有先行明确系统的宏观约束状态,才能赋予微观统计以物理意义。热力学第一、二定律不仅是能量守恒与耗散的经验总结,更是为系统演化划定了“可能”与“不可能”的绝对边界。通过引入特性函数,我们将复杂的物理环境抽象为简洁的数学表达式:内能 U(S, V, N)对应孤立背景,而吉布斯自由能 G(T, P, N) 则完美契合了恒温恒压的现实实验室条件。而麦克斯韦关系式的对称美:
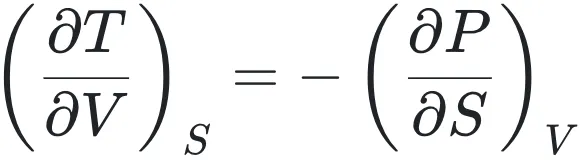
3)系综进阶:物理系统的重构
在前文的基础之上,逻辑阶梯进入了革命性的阶段:系综理论与公理化假设。这也是李永乐教授课程的核心论域——即如何通过概率逻辑重构物理系统。
对于一个完全孤立的系统,统计物理掷下了它的逻辑骰子:等概率原理。在这一假设下,熵被重新定义为玻尔兹曼公式:S = kB lnΩ这里的 Ω 代表给定能量下系统所能占据的微观状态总数。这是逻辑阶梯上最关键的跨越,它成功地将物理演化问题转化为组合数学的计数问题,赋予了热力学第二定律以统计学的灵魂。
随着系统与外界环境交互方式的改变,系综理论呈现出递进的逻辑层次,如图2所示,我们可以大致分为五种统计系综:三种正则系统与等压等温(类似实验室系统)与等焓等压系。当系统与庞大的热库接触时,能量的交换使得单一能量状态不再恒定,系统进入正则系综。此时,系统处于某一能量状态的概率不再相等,而是服从玻尔兹曼分布:
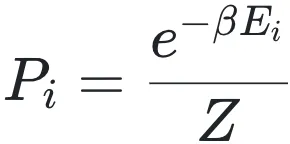
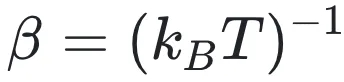
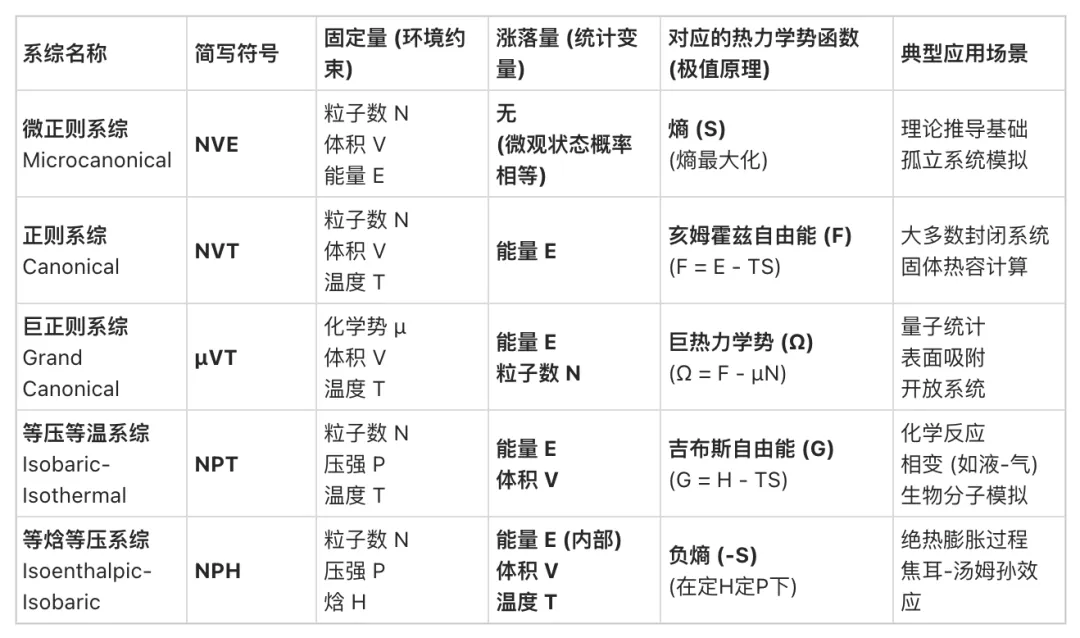
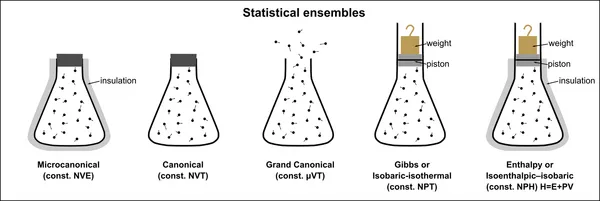
图2 不同系综对比示意图(从左到右):微正则系、正则系、巨正则系、等压等温系、等焓等压系
在整条统计物理的逻辑链条中,配分函数Z扮演着连接微观能级与宏观观测量的“唯一中介”角色。对于正则系综,配分函数的定义不仅仅是一个求和式:
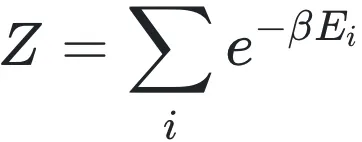
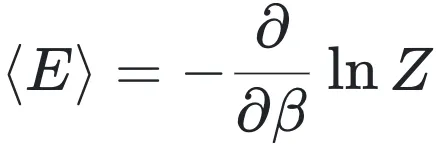
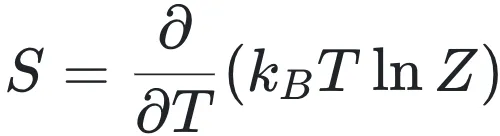
4)量子系统:新的规则?
当进入微观粒子的量子领域,经典的连续分布被离散的量子态取代。当德布罗意波长与粒子平均间距接近,粒子波函数开始重叠,粒子变得不可区分,全同性原理便开始占主导地位。此时必须区分两类粒子:费米子与玻色子。费米子交换两粒子时,波函数变号(反对称),而玻色子交换两粒子时,波函数不变(对称),这两种粒子会导致截然不同的统计行为。直观来看三者在分布上存在显著差异,如图3所示,横轴表示能级相对于化学势的无量纲能量差,反映粒子占据该能级所需付出的热学代价;纵轴表示在热平衡条件下单位能级上的平均粒子数。蓝线为玻色–爱因斯坦分布,低能区占据数迅速增大,体现玻色子可无限聚集的量子特性,是玻色–爱因斯坦凝聚的基础;红线为费米–狄拉克分布,低能区占据数受限于不超过 1,体现泡利不相容原理;橙线为玻尔兹曼分布,对应经典极限。在高能区三条曲线逐渐重合,表明量子统计在高能或高温条件下统一回归经典行为。
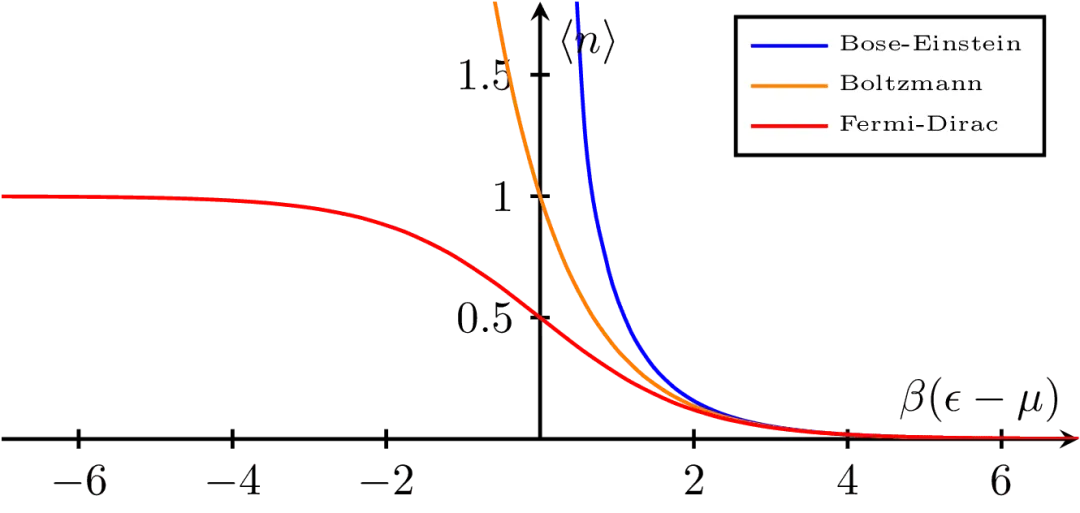
图3 平均占据数 ⟨n⟩ 与 β(ε−μ)的关系(β=1/kT,μ 为化学势):Bose-Einstein分布(蓝)显示低能级的强聚集趋势,Fermi-Dirac分布(红)受泡利不相容限制,Maxwell-Boltzmann分布(橙)给出经典稀薄极限。
而量子全同的真正影响在于:它改写了统计物理最底层的“状态计数规则”——同类粒子交换不再产生新微观态,并且玻色子/费米子分别允许或禁止同一量子态的重复占据。由于熵本质上是Ω的对数、而配分函数Ζ是对所有允许微观态的加权求和(量子情形为在对称/反对称态空间上取迹),一旦计数规则改变,Ω、Ζ、以及由Ζ导出的内能、热容、涨落乃至相变门槛都会随之改变。所谓“高温回归经典”,正是因为在稀薄极限下占据数很小,这些量子计数限制几乎不再被触发。
5)真实世界:涨落无处不在
经典的平衡态统计物理构建了一个静态的理想框架,但真实的物理世界往往处于剧烈的涨落与演化之中。在李永乐教授课程的后半部分,我们将视角转向更复杂的物理图景。
首先是相变——这是平衡态中“涨落”由量变引起质变的时刻。当外部参数跨越临界点,系统内部的关联长度趋于无穷,微观涨落不再相互抵消,而是宏观涌现,导致对称性自发破缺。朗道理论通过“序参量”巧妙地捕捉了这种秩序的生灭。更进一步,当我们真正踏入非平衡统计物理的大门,我们不再仅仅关注状态的概率分布,更关注系统对外界的响应。这里存在一个连接平衡与非平衡的宏伟桥梁——涨落-耗散关系。它告诉我们:系统在平衡态下自发的“涨落”特性,直接决定了它在非平衡条件下对外界扰动的“耗散”能力(如电阻、粘滞)。这种深层的统一性,正是统计物理从静态走向动态、从结构走向演化的关键一步。
至此,从微观到宏观、从经典到量子、从平衡到非平衡,统计物理的逻辑阶梯终于搭建完毕。
统计物理的基础框架是一套严密的自洽逻辑体系。李永乐教授主讲的《统计物理基础》课程,正是遵循上述逻辑阶梯,通过“问题驱动”的方法,将枯燥的公式还原为生动的物理直觉。
对于初学者: 重点在于理解系综理论如何从统计平均中“涌现”出宏观定律。
对于进阶者: 核心在于掌握配分函数这一工具,去处理如复杂流体、磁性材料乃至神经网络模型等前沿问题。
四、 跨学科的应用前沿:
当生成模型遇见非平衡态统计
四、 跨学科的应用前沿:
当生成模型遇见非平衡态统计
在传统视野中,统计物理处理的是物质实体,而人工智能处理的是信息数据。然而,随着深度学习尤其是生成式扩散模型的横空出世,这两者的界限正在被数学逻辑打破。2025年1月发表Physical Review E上的一篇研究[7],让我们看到了一幅统计物理与深度学习完美交融的图景。
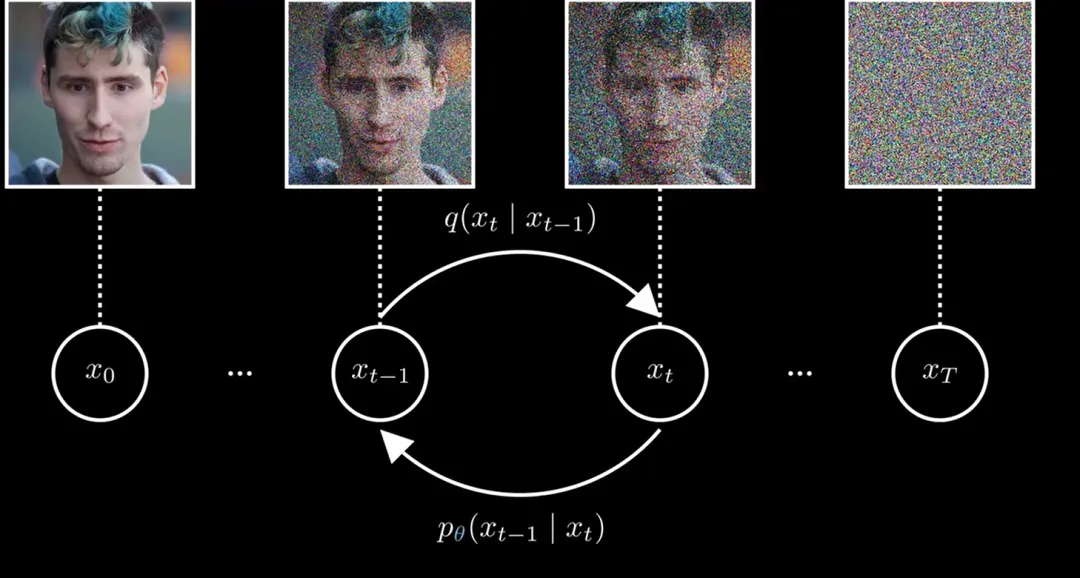
图4 扩散模型示意图。从左到右,前向扩散过程,熵增;从右到左,逆向生成过程,熵减。
该研究的核心洞见在于,将AI生成图片的逆向过程,精确映射为物理学中的朗之万动力学(一种引入了随机热噪声的运动方程)。如图4的扩散模型示意图中,我们可以把前向过程想象为一滴墨水在清水中扩散,这是一个熵增的、趋向无序高斯分布的自然过程;而扩散模型的魔法,在于通过学习一个“力场”,强行让时间倒流,从混沌的白噪声中“逆流而上”重构出有序的数据结构。这不仅是算法的胜利,更是非平衡态热力学的直接体现。
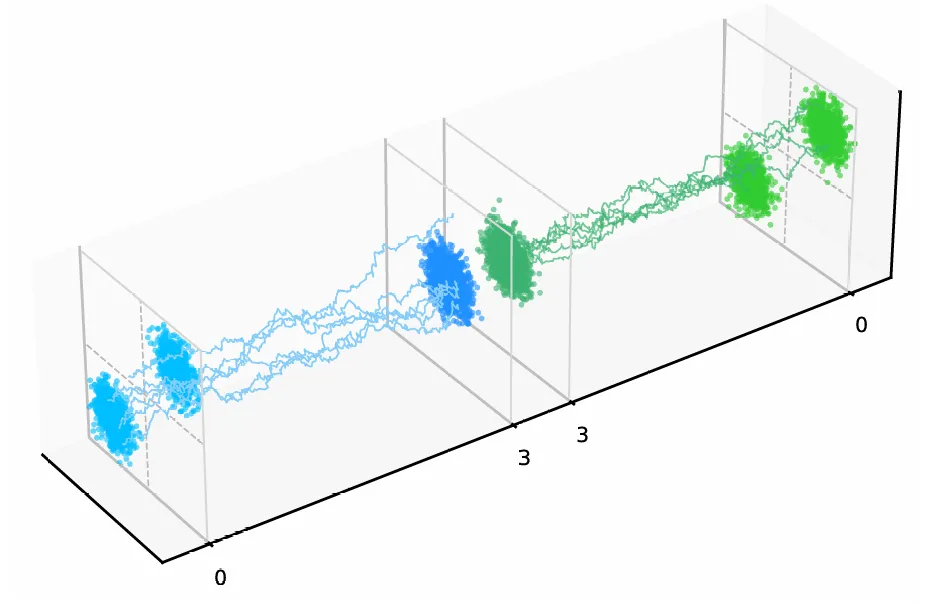
图5 二维高斯混合数据生成扩散过程的示意图。包括从时间t = 0到时间t = 3的前向扩散过程与从时间t = 3到时间t = 0的逆向生成过程。
如图5所示,研究利用二维高斯混合数据生成扩散模型来模拟人工智能需要处理的、经过“熵增”的信息数据(蓝色轨迹),那么算法是如何在混乱的数据流中“逆行“复原出有序结构的呢(绿色轨迹)?究其原因,他们是利用路径积分与自旋玻璃理论,特别是Franz-Parisi势能,揭示了生成过程中存在的动力学相变。研究指出,数据生成的各个阶段并不均等:在去噪的初期,系统处于类似于“顺磁相”的无序状态,演化是线性的、平庸的;但随着噪声降低跨越某一临界点,系统发生自发对称性破缺,进入类似于“铁磁相”的吸引子区域。此时,模糊的像素突然坍缩成清晰的语义特征——正如过冷水瞬间结冰。这种物理视角的引入,不仅量化了生成过程中的熵产生与能量消耗,更为我们理解神经网络如何从庞大的相空间中“锁定”现实世界,提供了一个基于物理第一性原理的解释。这再次证明,统计物理不仅是描述原子的语言,也是理解智能涌现的语法。
注:以上图源均来自网络 (除论文标注外)
参考文献