行走、跑步、扭秧歌,已成为当前人形机器人的主要展现形式,但此类动作仍处于相对缓慢和简单的运动范畴。若要实现更多应用价值,机器人还需具备旋转、腾跃等高难度技巧,能够快速切换重心,进行诸如舞蹈、功夫等高动态行动。
然而,要让机器人完成“回旋踢”动作并非易事。这涉及快速身体运动、复杂控制力及精准平衡调节,对机器人的软硬件系统提出了极为严苛的要求,稍有不足,就会跟不上节奏或直接失控。

TeleAI功夫机器人
为攻克上述难题,中国电信集团CTO、首席科学家、中国电信人工智能研究院院长李学龙教授带领具身智能团队展开深入研究,并于近日开源了一项类人行为驱动的人形机器人全身运动控制框架PBHC(Physics-Based Humanoid Control),让机器人在物理真实感下稳定复现高动态全身动作。这不是给机器人贴动作标签那么简单,而是让它真正掌握动作的节奏、力量、接触控制与动态平衡等一整套复杂策略。
从动作筛选到智能追踪
PBHC 框架分为两大核心阶段,即“对人类动作进行物理可行性处理”和“引入自适应动作追踪机制”。前者是指从视频中提取动作后,利用一套基于物理指标的筛选和修正流程,去除超出机器人物理限制的部分,并通过逆运动学将动作“转译”给机器人;后者则通过动态调整追踪精度和奖励函数,逐步让机器人学会在“合理范围内尽可能模仿”,而不是盲目逼近“完美复制”。
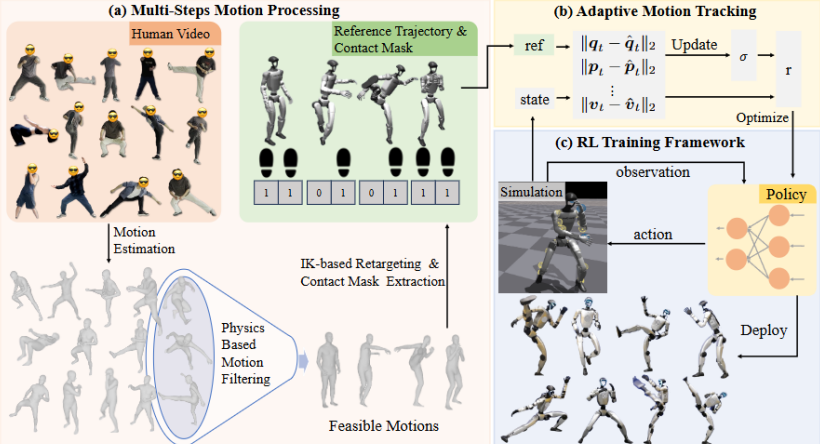
PBHC整体框架概览
在这一过程中,TeleAI团队设计了非对称Actor-Critic结构:Critic端可使用特权信息提升策略估值,而Actor则仅靠局部观测执行控制,确保该方法具有更强的部署可行性。
对机器人来说,模仿人类动作并不是“喂个动作数据就能学”这么简单。人类动作往往不顾物理限制,直接模仿会出现“膝盖超伸”或因重心不稳直接飞出去。为此,PBHC 框架设计了一条完整的动作处理流水线,目的是将“看得见的动作”转化成“做得出的轨迹”。
这一流程分为四个步骤:
第一,从视频中恢复SMPL动作。使用GVHMR方法提取3D姿态序列,该方法可对齐重力方向,也能缓解脚滑等重建误差;
第二,物理稳定性筛选。通过估算质心(CoM)和压力中心(CoP)的投影距离,判断动作是否物理可行。如果动作中CoM和CoP经常偏离,则判定为不稳定动作,将直接剔除;
第三,基于接触掩码的动作修正。通过检测双脚是否稳定贴地(基于速度阈值与高度判断),修正上下漂浮问题,并通过指数平滑避免抖动;
第四,动作重定向。使用微分逆运动学方法将SMPL动作映射到机器人关节空间,同时保留动作结构并遵守力学与运动限制。

开放动作数据集(左)AMASS(右)LAFAN
为提升数据多样性,TeleAI团队引入了AMASS、LAFAN等多个开放动作数据集。部分动作经过接触修正与重定向,保障了后续模仿策略训练的输入是物理合理、动态可控的。
对于高动态动作模仿,真正难的不是“动得快”,而是“动得刚刚好”。一味强求精准模仿,反而会导致控制不稳甚至系统崩溃。PBHC 框架在这一点上非常有见地:不是所有动作都能完美追踪,有时候退一步,反而能走得更远。
为此,TeleAI团队设计了一种自适应动作追踪机制,通过动态调整奖励函数中的追踪容忍度(Tracking Factor),实现“难易度感知式”的模仿学习策略。
01指数型奖励函数
在PBHC框架中,模仿精度不再用传统的负误差函数(-x)来衡量,而是引入更柔和的指数函数:r(x)=exp(-x/σ)。x是追踪误差(如关节角度的MSE),σ是“追踪因子”,也就是误差容忍度。
如果σ很小,哪怕误差稍大一点,奖励就几乎归零,学习会变得不稳定;如果σ太大,奖励就不敏感,控制器就会“得过且过”。所以,关键是找到一个“刚刚好”的σ。

数据集中的示例运动
02Bi-Level优化问题
与其人工调参,不如让系统自主学习。TeleAI团队将Tracking Factor的选取建模为双层优化问题(Bi-Level Optimization)。下层问题是在给定的σ条件下,学习一个追踪误差最小的策略;上层问题是基于学出来的策略,反向优化σ以实现整体误差最小。
尽管理论上可以这样建模,但σ和策略本身存在耦合,直接求解并不现实。为此,PBHC框架引入了在线EMA估计机制。即在训练过程中,系统维护一个指数滑动平均的追踪误差值,并在每一步利用该均值更新σ,同时将σ设定为逐步收紧(非递增),形成一个“误差越小→σ越紧→学得越细致”的闭环。
这套机制就像一个“动态进阶教练”——刚开始要求不高,让机器人先学会基本动作,学到一定程度后,再逐步提高标准,让策略精度稳步提升。
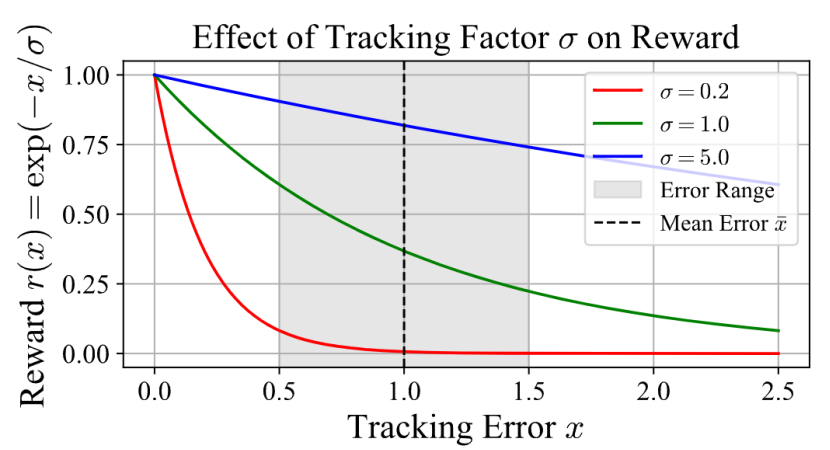
追踪因子σ对奖励数值影响的示意图
这种自适应机制能有效提升训练稳定性和最终模仿质量。
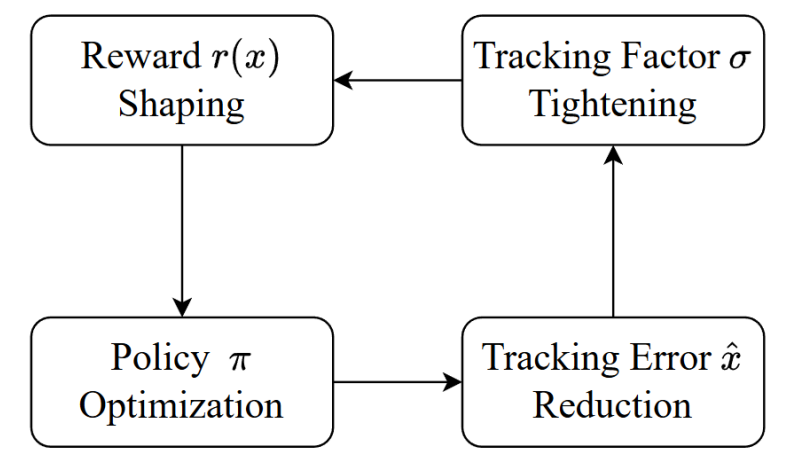
自适应机制中追踪因子的闭环调整过程
在完成动作配置及追踪机制后,关键在于训练出听得懂动作、做得出控制的策略。PBHC框架采用了一套结合多项强化学习技巧的训练架构,旨在提升效率、加速收敛并实现落地应用。
01非对称Actor-Critic
PBHC框架延续了许多高性能RL控制方法中的经典思路,如Actor-Critic非对称结构。
Actor(执行者):只观察机器人自身的运动状态(如关节角度、速度、重心、历史动作等)与当前所处动作的时间段,相当于用“局部信息”做决策。
Critic(评估者):拥有“特权信息”,能感知更多维度,包括动作参考轨迹、身体线速度,甚至模拟物理参数。
该架构的意义在于:训练时让Critic看得更全,以提升价值估计;而部署时只用Actor,保证实际可行。
02奖励向量化
PBHC框架并未将所有奖励指标加权合并为一个总奖励,而是选择了奖励向量化策略:将每个Reward分量(如关节追踪、平衡保持、接触一致性等)分别传入Critic中的独立输出头。每个分量对应一个独立的价值函数,最后再综合评估动作优势。
这种设计有两个好处:一是提高策略学习的细致程度,每项目标都能被精确优化;二是提升整体训练稳定性,减少Reward编码冲突导致的不确定性。
03引入参考状态初始化
为提升训练效率,PBHC框架采用RSI技术:当Episode初始化时,随机从参考动作序列中抽取一个时间点,并将机器人初始化到该状态。此举可打破时序依赖,让策略能在各个动作阶段并行学习,尤其适用于那些包含跳跃、转身、起伏等变化激烈的动作。
04零样本部署
在策略迁移方面,PBHC框架并没有引入额外的修正模块或实机微调,而是采用了经典的Domain Randomization策略:在仿真训练中,对机器人物理参数、摩擦系数等数据进行扰动,提升策略对环境变化的鲁棒性。
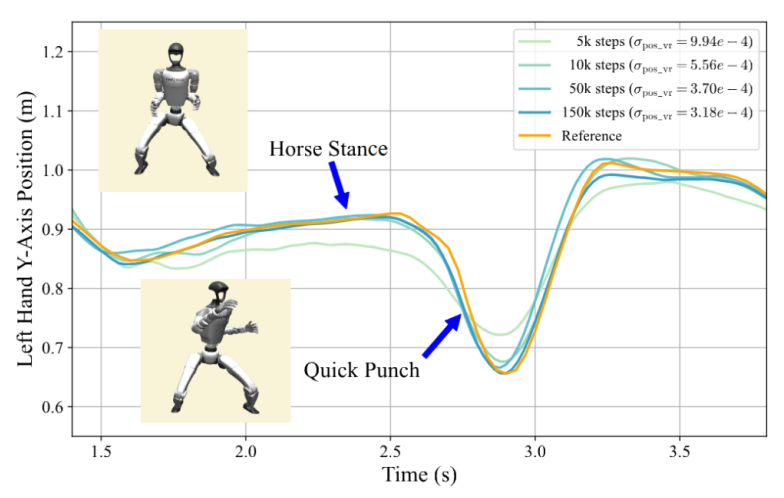
“马步冲拳”动作中右手y轴位置示意图
在实机实验中,机器人不仅复现了高动态功夫与舞蹈动作,还能保持稳定和平衡。

机器人复现“马步冲拳”动作
跑得动、仿得像、落得稳
针对PBHC框架的有效性,TeleAI团队围绕四个方面进行系统性验证。
01物理筛选机制
为验证物理筛选机制的实用性,TeleAI团队对一组从视频中提取的动作序列进行筛选处理,实验结果显示,10个动作中有4个因物理稳定性不足被剔除,其余6个保留用于训练策略。
通过计算训练轨迹与参考轨迹长度比值(Episode Length Ratio,ELR),发现被保留的动作成功率远高于被剔除的动作,后者最高ELR仅有54%。
这说明物理筛选不仅提高了训练效率,也避免了策略在“学不会的动作”上反复试错。
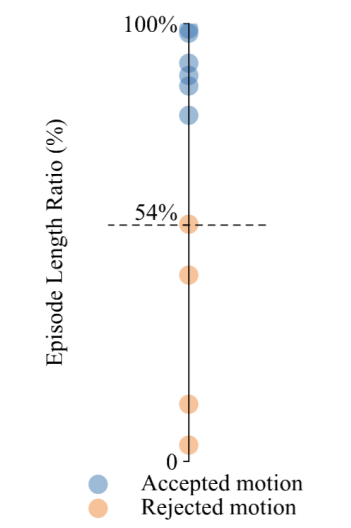
训练轨迹与参考轨迹长度比值
02PBHC框架多项指标全面领先
将PBHC框架与OmniH2O、ExBody2及MaskedMimic三种方法进行系统对比,评估指标覆盖位置、速度、加速度、关节状态等六项误差指标。结果显示:
PBHC框架在所有指标上均优于OmniH2O与ExBody2,其优势主要来自自适应追踪机制的引入,使策略能自动调整精度要求,更具泛化能力。
MaskedMimic虽部分指标表现尚可,但其设计目标为动画生成,不适用于实际机器人部署,因此仅作为理论下限参考。
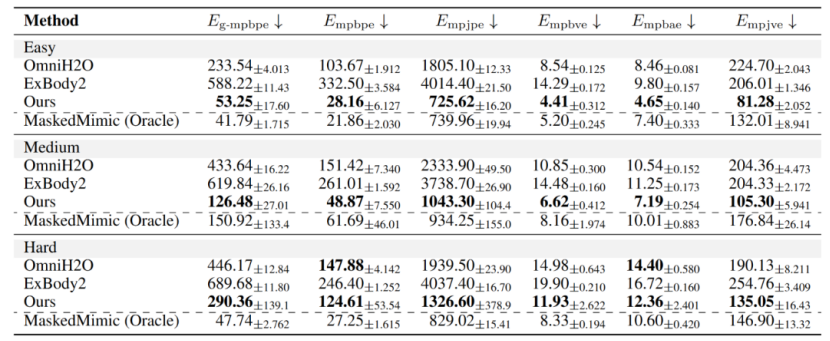
对比数值实验结果
03自适应追踪机制优势
为验证自适应Tracking Factor的价值,TeleAI团队设计了一组消融实验,对比使用固定σ的四个版本(粗略、适中、上界、下界)与PBHC框架的自适应策略。
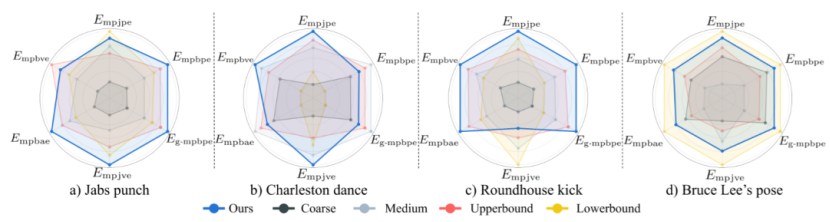
消融实验结果
结果显示,固定σ的表现会因动作类型变化而波动,有的设定在A动作上有效,在B上却失效。而自适应机制则在所有动作类型中都保持了近似最优的追踪性能,体现出自动调节精度策略的稳健性与泛化能力。
该机制就像一个“可变难度的老师”,知道何时放松标准让机器人先学动作,什么时候收紧标准强化控制精度,是PBHC框架能跑出表现力的关键。
04真实部署表现亮眼
在真实机器人的部署表现上,PBHC框架展示了令人惊艳的全身控制能力:拳法踢腿(如连续出拳、正踢、跳踢、回旋踢)、动态动作(如360°旋转)、柔性动作(如下蹲、伸展)、表演动作(从力量型舞蹈到优雅的太极套路)。
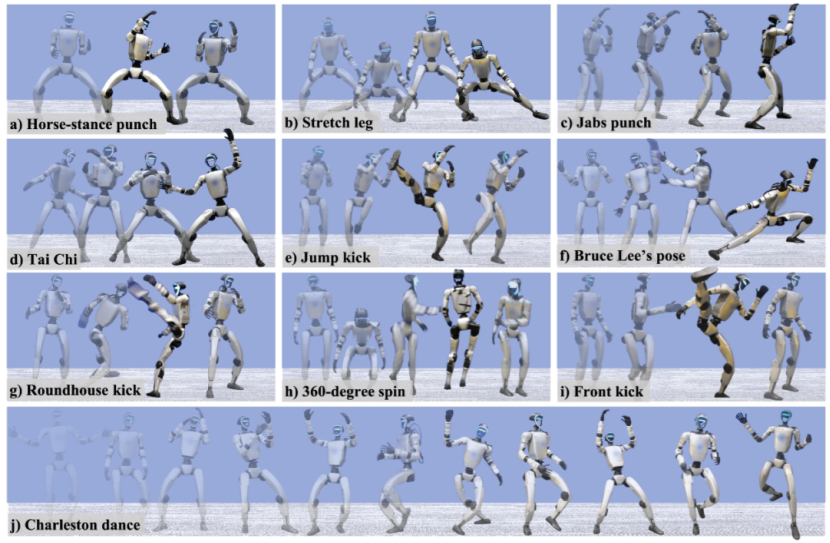
真实环境部署效果可视化
TeleAI团队还进行了太极动作的实机定量测试,其误差指标与MuJoCo仿真中的结果高度一致,说明策略具备良好的Sim-to-Real迁移能力,无需任何微调即可落地。
TeleAI团队提出的PBHC框架为人形机器人的创新和应用提供了一条物理真实、可部署性强的模仿路线。该框架通过动作预处理,自适应追踪控制、强化学习策略训练,最终实现了高动态、稳定、具有表现力的全身模仿。
无论是复杂拳法还是舞蹈动作,PBHC框架均展现出远超现有方法的追踪精度与实机表现力。该框架提供的不只是一个控制框架,更是一种基于物理感知驱动高动态控制的思路,对今后人形机器人的可控性与表现力提升将带来极强的启发意义。