应聘时“包装”自己?人格测评防作弊新神器让你无处遁形!
想象一下这样一个场景:
面试一份心仪的工作,终于到了“人格测试”环节。看着那些“您是否能按时完成任务?”“您能否承受高压?”的问题,心里的小算盘打得噼啪响:“当然要选‘非常符合’啊!难道选‘不符合’等着被刷吗?!”
于是,你信心满满,以为能瞒天过海,把答案朝着“社会赞许”(social desirability)的方向一路狂奔... 恭喜你,你正在进行心理学界所说的虚假作答(Faking),俗称“装好”。

请输入图片描述
试问:这种“装好”真能骗过科学测评吗?
传统的人格测评(Likert量表,就是让你从“非常不符合”到“非常符合”打分)作答者可以通过“装好”来得到较理想的结果。于是心理学家们发明了迫选测验(Forced Choice Measures)来应对。它长这样:
请从以下描述中,选择最符合你的一项:
A. 我总能按时完成任务 (测量责任心)
B. 我擅长活跃聚会气氛 (测量外倾性)
C. 我常常思考人生意义 (测量开放性)
ABC三个选项的社会赞许性(“好”的程度)被故意设计得差不多!选A显得有责任心,但可能暴露你不善社交;选B显得外向,但可能显得不够踏实...让你左右为难,难以“装”得完美!

请输入图片描述
BUT!这种“强迫选择题型”(即迫选测验)测试就能够完美防作弊了吗?
当然没那么简单!
选项/项目的“吸引力”会变化:单个项目(如“做事认真”),可能显得很靠谱,但是如果和“办事效率低”放一起,又可能显得不那么靠谱了。项目之间会相互影响发生变化(Guenole et al., 2018; Wetzel et al., 2021)。
道高一尺魔高一丈:即便所有选项都设置的差不多好,但是应聘者还是会在与目标工作最相关的特质上选择得分更高的选项(Cao & Drasgow, 2019)。
看碟下菜:大家在不同的情境下的“装好”也是不同的。比如应聘护士时大家会表现出自己有更高的“宜人性”,而应聘销售经理岗位时则会强调“外向”(Pauls & Crost, 2005)。
这意味着,迫选测验虽然相比Likert测验更难作弊,但依旧不能完全防“装好”。这些虚假作答行为会严重降低测试结果的准确性与公平性。
如何破局?给迫选测验装上“防伪探测器”!
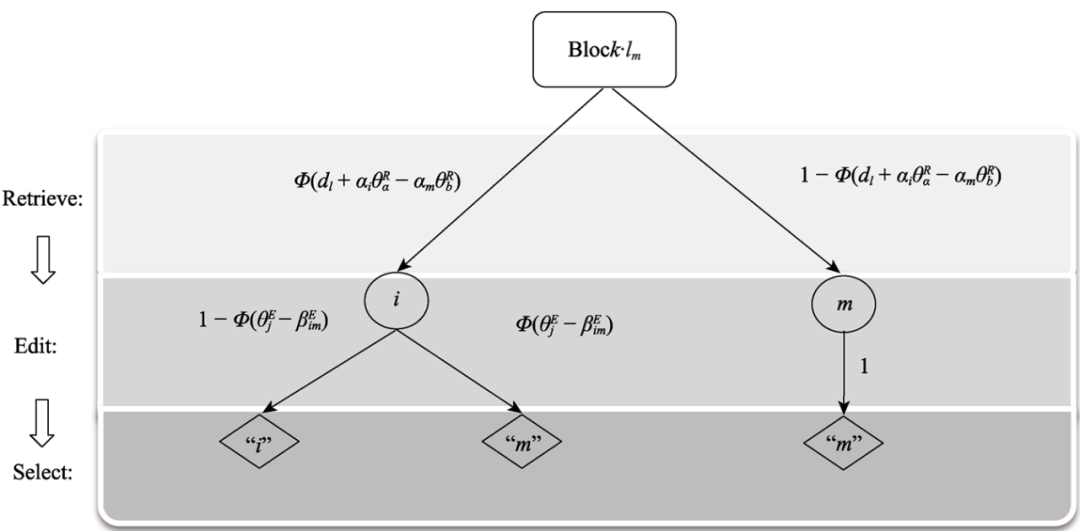
本研究创新性地融合了瑟斯顿IRT模型(Thurstonian IRT, TIRT;Brown et al.,2011)与虚假作答的“检索-编辑-选择”理论模型(Retrieve-Edit-Select, RES;Böckenholt,2014),开发出针对迫选测验中虚假作答行为的新模型——RES-TIRT模型。它就像给迫选测验装上了一个“测谎仪”。

请输入图片描述
这个模型是怎么抓“装好”?
它通过深入分析你做题时的心理活动过程:
初始反应:看到题目时,你的脑海中浮现的真实信息或想法(“我其实不是总能按时完成任务”)。
犹豫不决:你纠结是否要为了获得目标工作修改答案,让自己显得很适合这个岗位。
做出选择:最后你提交了答案,可能是真实内心想法,也可能是“包装”过的。
专门捕捉你在犹豫不决内心挣扎的那一步小动作:
不仅能估计你的真实人格特质水平 (θ^R),
还能看出你的“虚假作答倾向” (θ^E)有多强,
更强大的是,它能够通过β^E值找出哪些题目容易让人“装好”。应聘律师时,遇到“我喜欢解决复杂问题”vs“我能够展现出很大的热情”更容易让人作假,选择“我喜欢解决复杂问题”而面对“我喜欢陷入沉思”vs“我经常做最后计划”就比较难“装”。
请输入图片描述
图1 新模型(RES-TIRT)建模框架
注:加粗的项目表示具有更高的称许性
这项研究有什么用?让测试更加公平准确:
1) 提高迫选测验“防作假”能力:这是一个专门针对迫选测验“装好”问题的新模型。它让原本具有一定防作假能力的迫选测验防御力更上一层楼。
2) 双保险:在出题时精心设计选项匹配的基础上加上了统计建模,上了双保险,让结果更加真实可靠。
3)指导迫选测验开发编制:模型能直接告诉出题人:“这套题目里,这几道最容易让人‘装好’,得改”这样就能设计出更防作假的测验题。
参考文献:
Brown, A., & Maydeu-Olivares, A. (2011). Item response modeling of forced-choice questionnaires. Educational and Psychological Measurement, 71(3), 460−502.
Böckenholt, U. (2014). Modeling motivated misreports to sensitive survey questions. Psychometrika, 79(3), 515−537.
Cao, M., & Drasgow, F. (2019). Does forcing reduce faking? A meta-analytic review of forced-choice personality measures in high-stakes situations. The Journal of Applied Psychology, 104(11), 1347−1368.
Guenole, N., Brown, A. A., & Cooper, A. J. (2018). Forced- choice assessment of work-related maladaptive personality traits: Preliminary evidence from an application of Thurstonian item response modeling. Assessment, 25(4), 513−526.
Pauls, C. A., & Crost, N. W. (2005). Effects of different instructional sets on the construct validity of the NEO-PI-R. Personality and Individual Differences, 39(2), 297−308.
Wetzel, E., Frick, S., & Brown, A. (2021). Does multidimensional forced-choice prevent faking? Comparing the susceptibility of the multidimensional forced-choice format and the rating scale format to faking. Psychological Assessment, 33(2), 156−170.
推文作者:涂冬波,彭思韦,何翠婷,等
推文源文
何翠婷, 彭思韦, 朱怡安, 汪大勋, 蔡艳, 涂冬波. (2025). 迫选测验中虚假作答行为建模及其在人格测评中的应用:基于RES理论框架. 心理学报, 57(10), 1832-1848.
